تا به اینجا رسیدیم که کپچای تصویر متنی را با او.سی.آر به شکل ماشینی دور میزنند و به همین دلیل روشهای متفاوتی برای طراحی کپچا ارائه شده است. جالب است بدانیم که این روزها شرکتها و مراکزی وجود دارند که قیمتهای استاندارد (!) برای شکستن کپچای سایتهای مختلف ارائه میکنند. به عنوان نمونه این تکهای از لیست قیمت یک شرکت متخصص شکستن کپچاهای سایتهای چینی است (منبع عکس):

ماجرا محدود به کپچاهای تصویری هم نمیشود، کپچاهای صوتی هم توسط نرمافزارهای کامپیوتری -گویا به آسانی- قابل عبور هستند (در این نشانی مقالهای تفصیلی دربارهی نحوهی عبور از کپچای صوتی جیمیل بخوانید). کپچاهای تصویر متنی شرکتهای بزرگ (مایکروسافت، یاهو و گوگل) به دلیل تعداد کاربران بالا و همچنین اعتبار ایمیلهای ارسالی از آنها برای نرمافزارهای مبارزه با هرزنامهها بارها و بارها شکسته شدهاند (اینجا را ببینید).
اما کپچاهای ابتکاری چه؟! آیا مقاومت کپچاهای ابتکاری (کپچای محاسباتی، کپچای سهبعدی، سگ و گربهی رپیدشر و …) بیشتر نیست؟ آیا نرمافزارهای ارسال انبوه اسپم از این کپچاها هم میتوانند عبور کنند؟
تا اینجا و با توجه به سرمایهگذاریهای قابل توجه ارسال کنندگان اسپم روی کارشان باید به این نتیجه رسیده باشید که در این «شغل» آنقدر «پول» هست که نه تنها اجازهی استفاده از راهبردهای «تحقیق و توسعه» را برای شکستن سدهای پیش رو به آنها میدهد بلکه احتمالاً این درآمدها میتواند آنقدر زیاد باشد که حاضر باشند برای حل مشکلات پیشرو مستقیماً و عملاً نیروی انسانی در اختیار بگیرند و از کمک نیروهای کار ارزانقیمت کشورهای در حال توسعه استفاده کنند.
به پشتوانهی سرمایهی ارسال کنندگان اسپم در کشورهایی مانند هند شاهد ظهور یک صنعت درآمدزای بدیع هستیم: «صنعت حل کپچا»! اتاقهایی با بیست الی سی اپراتور که در ازای دستمزدهایی همچون «هر ۱۰۰۰ کپچا ۲ دلار» ساعتهای کاری خود را با بازخوانی کپچاها میگذرانند. فرایند کار به این صورت است که نرمافزار ارسال اسپم تصویر کپچا را جدا میکند، به یکی از اپراتورها میدهد، اپراتور مقدار آن را درج و ارسال میکند و نرمافزار، اسپمش را ارسال میکند. با این سیستم کاری، شرکتهای حل کپچای هندی ادعای حل روزانه تا ۵۰۰۰۰ کپچا یا بیشتر را به مدد چند ده کامپیوتر و اپراتور، و شیفتهای کاریی که ۲۴ ساعت ۷ روز هفته را پوشش میدهند دارند (برای کسب اطلاعات بیشتر اینجا را ببینید).
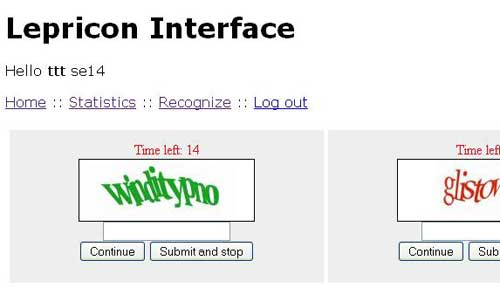
اینجاست که کارکرد کپچا برای جلوگیری از ارسال انبوه اسپم زیر سؤال میرود، چرا که کپچا برای حل این معضل، مبتنی بر این ایده است که ارسالکنندگان انبوه اسپم ماشین هستند و با تشخیص انسان از ماشین میتوان جلوی ارسال انبوه اسپم را گرفت. و در اینجا حداقل بخش سختتر کار را انسانها انجام میدهند.
دستهی دیگری از راهحلهای مقابله با اسپم بر «تحلیل متون ارسالی» مبتنی هستند. مقایسهی آی.پی ارسالکننده با لیست سیاه ارسالکنندگان اسپم شناخته شده، شمارش تعداد لینکهای موجود در متون و جستجوی نشانی سایتهای اسپم در بین آنها، بررسی محتوای متن و جستجوی واژههای متداول موجود در متون اسپم در متن ارسالی (یک آمار جالب در این زمینه را در این تصویر ببینید) از جمله ترفندهای به کار گرفته شده در این روش هستند. معمولاً برای جلوگیری از دور زدن شدن آسان الگوریتمها و روشهای مورد استفاده در این راهحلها بخش عمدهای از این روشها منتشر نمیشوند و تنها ابزارهای ارتباطی به صورت کدباز در اختیار استفادهکنندگان قرار میگیرند. «اکیسمت» سیستم مقابله با نظرات هرز که در وردپرس و برخی دیگر از سیستمهای مدیریت محتوی به کار گرفته شده است از جمله ابزارهای مبتنی بر این روش است.
این احتمالاً آخرین قسمت سری مطالبی بود که دربارهی «اسپم» نوشتهام. فهرست نوشتههای این سری:
قسمت اول: ریشهی نام اسپم
قسمت دوم: هرزنامهها
قسمت سوم: کدامیک هرزنامههای بیشتری میگیرند: «علی» یا «زهرا»؟
قسمت چهارم: بگذارید «اسپم»ها را آنها بخورند!
قسمت پنجم: درآمدزایی هرزنامهها
قسمت ششم: ماشینهای صاحبنظر
قسمت هفتم: کپچا: «تو آدمی؟!»
قسمت هشتم: او.سی.آر: قاتل کپچای تصویر متن
قسمت نهم: صنعت حل کپچای هند و راهحلهای مقابله با اسپم با تکیه بر تحلیل محتوی




{kind=link}